ebpf
什么是可观测性

对于一个苹果,我们说他是可观测的,当我们看着这个平果的时候 我们能够从中观察的到一些信息,例如
- 颜色
- 大小
- 形状
- 斑纹
如果是有经验的果农能还能知道苹果的品种,甜度,口感.
可观测性指的就是对于一个给定的物体,你能够通过各种手段进行观察,从而从中获取到更多的信息,从而加深对其的理解
Linux 可观测性
一个正在运行的操作系统,抽象的看大致由CPU 调度器/网络调度器/文件系统调度器三大部分组成,每个部分又通过各种系统调用为用户态程序提供接口。对于 linux 系统的观测,很大一部份就是对于这些模块的观测,问题在于,如何去观测?这次介绍的 EBPF 就为这种观测能力提供了手段
从BPF说起
需求: 网络包 过滤/监控
BPF工作流程
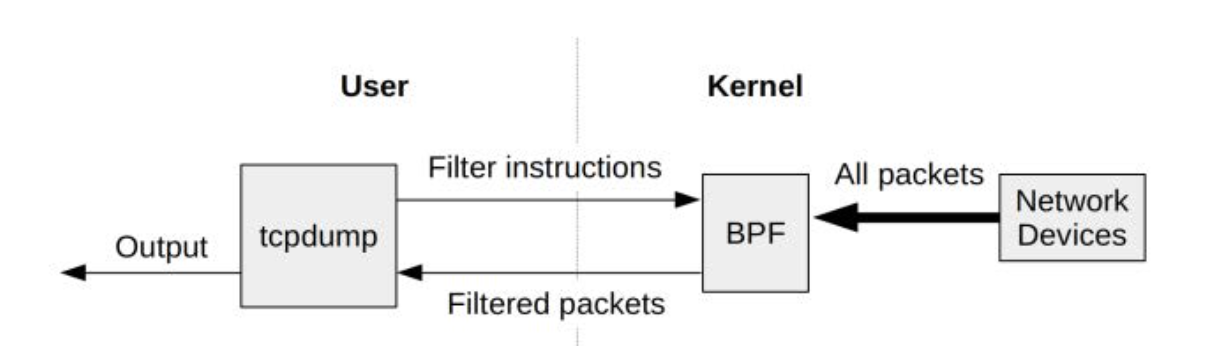 对于一个网络包 如果通过bpf过滤则保留,不满足则drop.
对于一个网络包 如果通过bpf过滤则保留,不满足则drop.
实现
- 内核虚拟机
- JIT编译
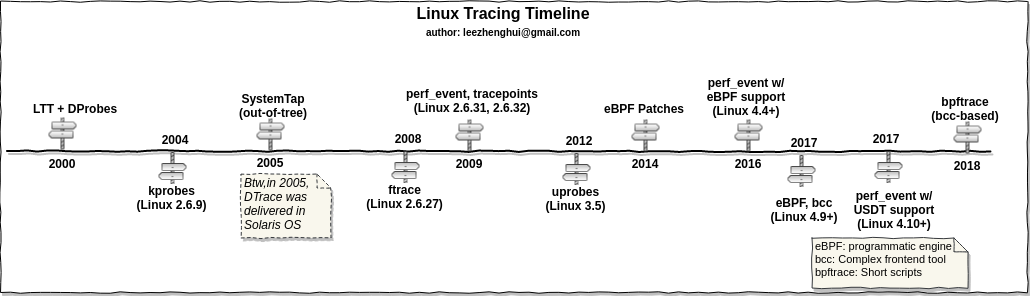
BPF历史
- 1992论文
<<A New Architecture for User-level Packet Capture>> - 1997 linux 2.1.75 add bpf
- 2011 linux 3.0 jit
工作模型
事件源(网络包)=>虚拟机=>(accept/drop)
事件源为什么一定是网络包?
事件源(linux hook)
KPROBE
linux内核空间系统调用,每一个内核态系统调用可以是一个事件源
UPROBE
linux用户空间(应用程序)调用,每一个用户态函数调用可以是一个事件源
trace-point
custom trace event,linux内核可以自定义事件
USDT
用户程序可以自定义事件
PMC 性能计数器(Performance monitoring counters)
CPU的性能采样计数器
- L1缓存成功/失败率
- 分支预测成功/失败率
KPROBE/UPROBE 原理
动态的改变linux内核指令流,插入一个int3指令(x86)从而跳转到probe逻辑.

- 通常来讲我们常见的hook点是函数入口和函数结束
- 因为kprobe通常被设置在函数入口点,所有我们也可以通过寄存器获取到这个函数的参数
trace-point原理
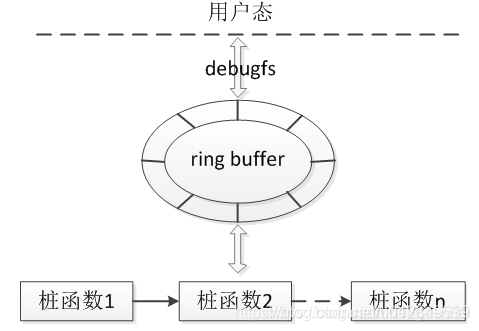
不同于kprobe
- tracepoint是内核代码中硬编码的,采用的是自己的一套注册hook的机制
- tracepoint比较稳定
USDT原理
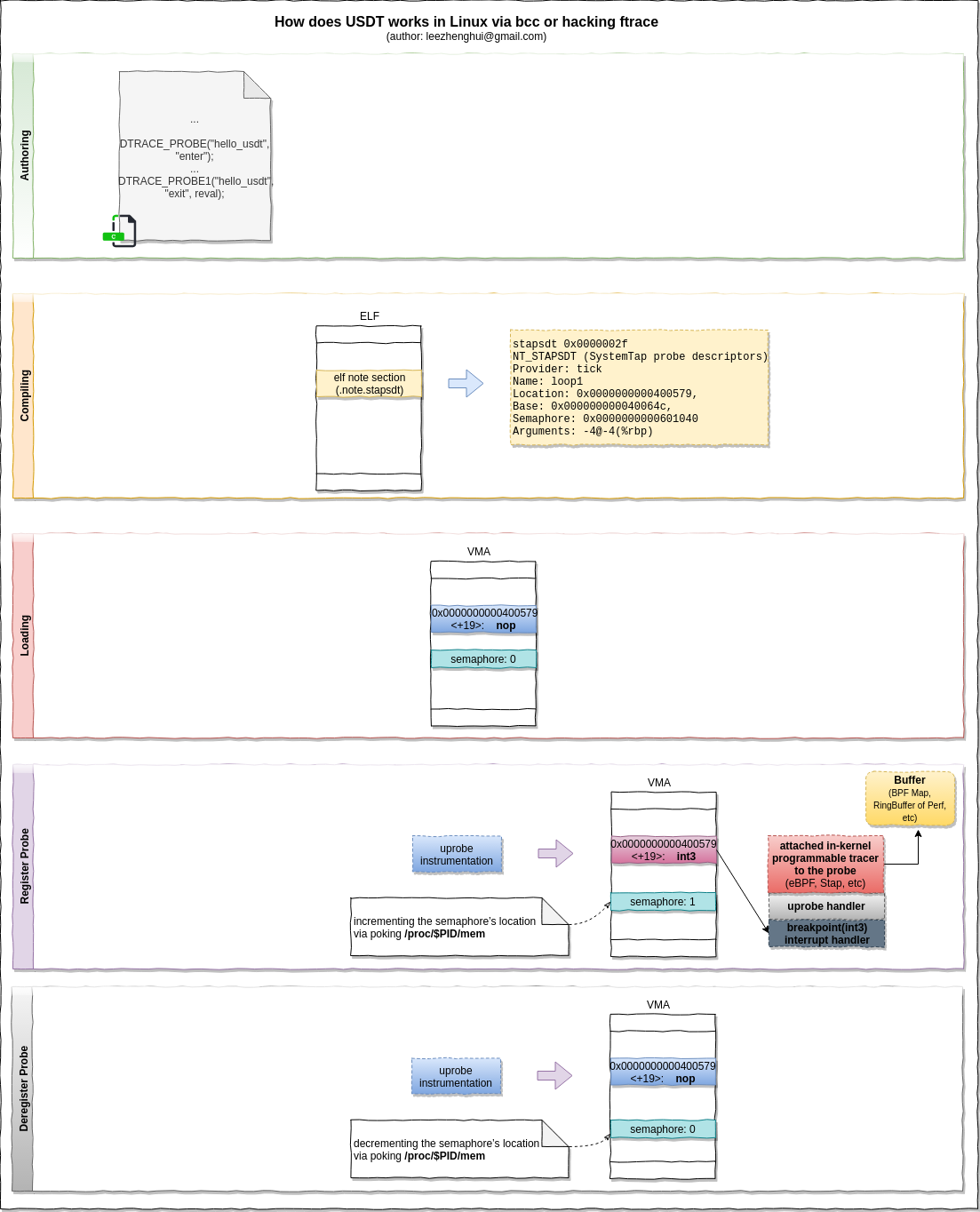
traceing system 历史
处理流程为什么一定是简单的匹配?
事件源(kprobe/uprobe/tracepoint/usdt)=>虚拟机=>(?)
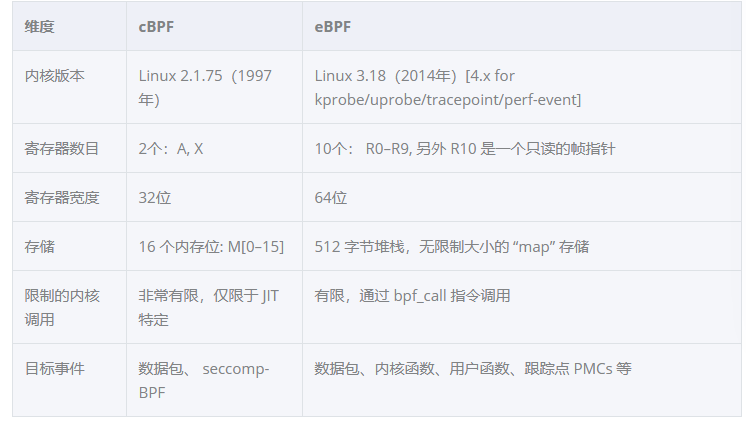
虚拟机对比
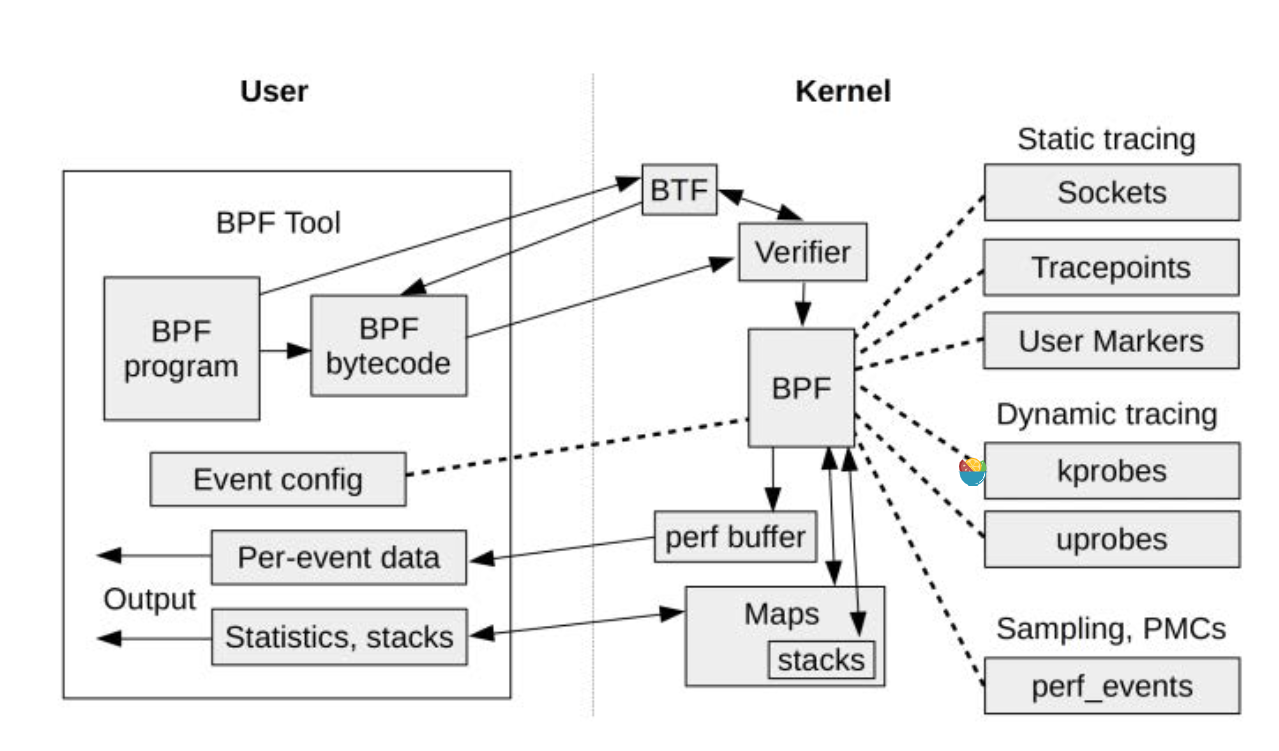
EBPF 工作流程
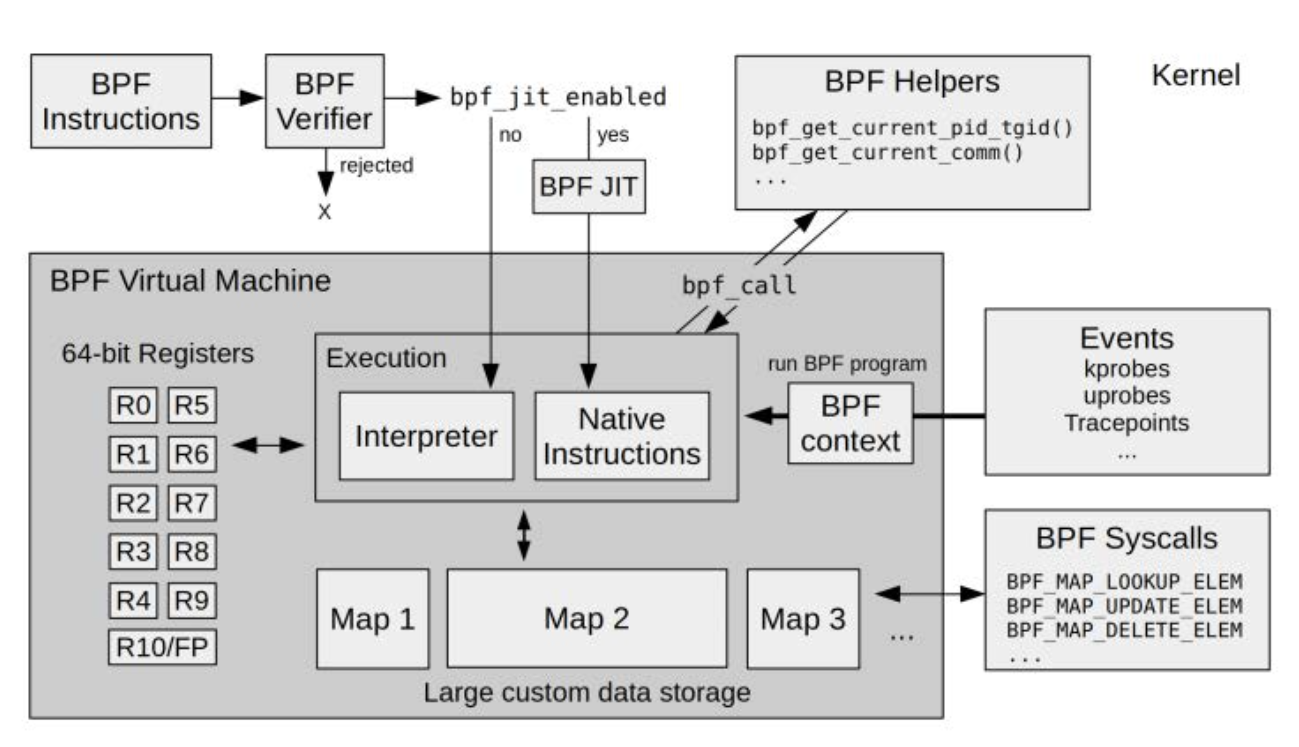
EBPF 工作流程
BCC/BPFtrace lib
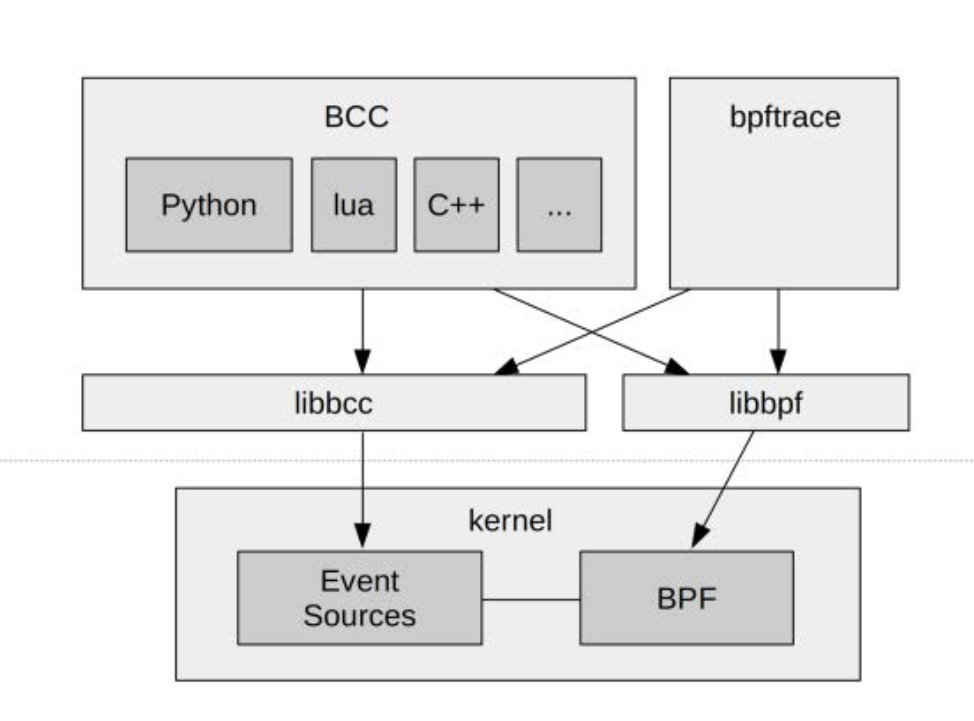
- LLVM
- bcc
- BPFtrace
BPFTRACE a lang for trace
#!/usr/local/bin/bpftrace
// this program times vfs_read()
kprobe:vfs_read
{
@start[tid] = nsecs;
}
kretprobe:vfs_read
/@start[tid]/
{
$duration_us = (nsecs - @start[tid]) / 1000;
@us = hist($duration_us);
delete(@start[tid]);
}但作为日常的使用,实际上我们还可以使用一种bpf特有的脚本语言 基本有三部分组成
- hook
- 对map的访问/基本条件控制语法
- bpf帮助函数
EBPF限制
- 循环次数 不能使用无限循环
- 堆栈大小限制
-
指令数限制 1百万条指令
EBPF其他用处
- SDN 软件定义网络 Cilium 基于EBPF实现的kube-proxy
lab
bcc tools
- execsnoop
- biolatency
bpftrace kernel mode
-
列出所有可以被设置trace的函数
sudo bpftrace -l '*kprobe*' -
跟踪udp协议 显示域名
sudo gethostlatencybpftrace uprobe bash readline
sudo bpftrace -e 'ur:/bin/bash:readline { printf("%s\n", str(retval)); }'